
La première information utile est "gestion de versions" : Le but principal d'un système de contrôle de version est de conserver un historique détaillé d'un projet ainsi que la possibilité de travailler sur différentes versions de celui-ci. Avoir un historique détaillé permet de voir l'avancement du projet au fil du temps. Si nécessaire, il est également possible de revenir à n'importe quel point du projet pour récupérer des données ou des fichiers. C'est également un outil robuste pour travailler à plusieurs sur des fonctionnalités différentes au sein en s'assurant de la perennité et de la compatibilité des données.
La deuxième information utile est la notion de logiciel décentralisé ou encore distribué. Pour faire simple, dans le cas d'un modèle centralisé, tous les utilisateurs se connectent à un serveur central appelé le dépôt maître pour interagir avec les données du projet. Dans le cas d'un modèle distribué, comme pour le logiciel Git, chaque utilisateur à l'ensemble des données du projet sur son ordinateur personnel.
Un système de gestion de versions conserve un historique détaillé de votre projet et permet de travailler sur différentes versions. Vous pouvez revenir à n'importe quel état antérieur du projet, comparer des versions et corriger des erreurs. Ce qui est particulièrement utile lors de travail collaboratif.
Un logiciel décentralisé comme Git permet à chaque utilisateur de disposer d'une copie complète du projet sur son ordinateur, contrairement à un modèle centralisé où tous les utilisateurs se connectent à un serveur unique.
Dans cette UE et dans vos projets futurs, Git vous permettra de :
Pour aller plus loin : Quels sont les avantages et les inconvénients des deux modèles : distribués et centralisés ?
Lorsque vous travaillez sur un projet, la plupart du temps vous êtes en local, sur votre machine. Dès que vous terminez une fonctionnalité précise, vous souhaitez la sauvegarder et l'intégrer à votre projet. Pour cela, Git propose la commande commit : elle permet d'enregistrer l'état de votre projet à un instant donné. Git prend alors un « cliché » de tous les fichiers ajoutés au commit et conserve une référence à cet instantané. C'est un point de sauvegarde de votre progression : toutes les versions précédentes restent accessibles, ce qui vous permet de revenir en arrière si nécessaire.
Le commit est donc l'unité fondamentale de Git. C'est l'action qui vous permet de faire évoluer votre projet étape par étape, en ajoutant des versions successives et cohérentes.
Le mot-clé repository ou repo désigne le dossier de travail suivi par Git. Ce répertoire peut exister localement sur votre machine ou sur un serveur distant (comme GitLab). Un dépôt contient l'ensemble de votre projet ainsi que l'historique de vos commits, et il évolue au fur et à mesure que vous travaillez.
Une branche (branch) est une ligne de développement indépendante. Elle vous permet de travailler sur une nouvelle fonctionnalité ou une correction sans modifier la branche principale (souvent appelée main ou master). Les branches facilitent le développement parallèle et la collaboration, et peuvent être fusionnées une fois prêtes.
Enfin, l'Index, ou zone de staging, est une zone intermédiaire entre votre espace de travail et l'historique Git. Vous y ajoutez uniquement les fichiers ou modifications que vous souhaitez inclure dans votre prochain commit. Cela vous permet de préparer des commits précis et cohérents, sans inclure par inadvertance des fichiers non pertinents.
Nous allons maintenant créer un projet et le connecter au GitLab de l'école : https://gitlab.cnam-enjmin.fr/
git config --global user.name "Mon Nom"
git config --global user.email "votreemail@votreemail.com"
git init.
Vérifier ensuite que le dossier .git a bien été créé dans le dossier en affichant tous les éléments
grâce à la commande ls -a sur Linux et grâce à la commande dir -h sur Windows PowerShell.
~/Desktop mkdir usrs46
~/Desktop cd usrs46
~/Desktop git init
Initialized empty Git repository in C:/Users/Azerolie/Desktop/usrs46/.git/
~/Desktop/usrs46 (main) ls -a
./ ../ .git/
~/Desktop/usrs46 (main) git status
On branch main
No commits yet
nothing to commit (create/copy files and use "git add" to track)
La commande git status permet de vérifier l'état du dépôt.
On apprend avec cette dernière commande que l'on se trouve sur la branche Main ou Master en fonction de votre configuration et qu'il n'y a pour le moment aucun commit. Cette branche est la seule disponible en début de projet, les commits vont s'organiser les uns derrière les autres le long d'une chaîne virtuelle (voir l'illustration ci-dessous après la réalisation de 4 commits).

touch helloworld.txt sur Linux et echo "Hello World!" > helloworld.txt sur Windows.~/Desktop/usrs46 (main) touch helloworld.txt
~/Desktop/usrs46 (main) git status
On branch main
No commits yet
Untracked files:
(use "git add file..." to include in what will be committed)
helloworld.txt
Git détecte qu'il y a un nouveau fichier dans le dépôt usrs46 mais que ce fichier n'est pas tracké par Git. C'est-à-dire qu'il n'est pas encore ajouté à votre branche principale et qu'il n'est donc pas encore concerné par la gestion de version.
Nous allons ajouter ce fichier à la zone de staging.
~/Desktop/usrs46 (main) git add helloworld.txt
~/Desktop/usrs46 (main) git status
On branch main
No commits yet
Changes to be committed:
(use "git rm --cached file..." to unstage)
new file: helloworld.txt
Le fichier est maintenant prêt à être commité. Vous pouvez faire un commit grâce à la commnde
git commit -m "message" :
~/Desktop/usrs46 (main) git commit -m "Mon premier commit ! Un Hello World !"
[main (root-commit) fccac00] Mon premier commit ! Un Hello World !
1 file changed, 0 insertions(+), 0 deletions(-)
create mode 100644 helloworld.txt
Le commit enregistre l'état des fichiers suivis dans l'historique local du dépôt Git.
Un pointeur appelé HEAD est utilisé par Git pour indiquer où vous vous trouvez actuellement dans l'historique des commits. En général, HEAD pointe vers le dernier commit effectué sur la branche en cours. Lorsqu'un nouveau commit est créé, HEAD est automatiquement mis à jour pour pointer vers ce nouveau commit.
Cependant, HEAD n'est pas toujours fixé au dernier commit d'une branche. Il peut aussi être déplacé manuellement vers un commit plus ancien dans l'historique. On dit alors que HEAD "remonte" dans l'arborescence des commits. Cela permet, par exemple, de revenir à un état antérieur du projet, d'explorer une autre version, ou de corriger des erreurs.
La commande git commit prend donc tout le contenu des fichiers qui ont été indexés avec
git add et enregistre un nouvel instantané permanent dans la base de données. Ce commit est identifié de manière unique par un identifiant SHA-1, ici fccac00. Le pointeur HEAD est déplacé automatiquement vers ce nouveau commit pour le référencer comme le commit reflétant l'état actuel du dépôt.
Pour bien comprendre, il faut revenir à la notion de commit et surtout de bon commit. Qu'est-ce qu'un commit de qualité au regard de git ? Est-ce que développer en sous-marin l'entièreté d'un projet et, une fois celui-ci terminé, tout envoyé à Git en un seul commit est une bonne idée ? Laissez moi vous aiguiller : Non ! Non ! Et non ! C'est à l'opposé galactique de ce à quoi sert un logiciel de gestion de versions. Un bon commit doit répondre aux deux points suivants :
On s'assure ainsi d'avoir des commits:
Lorsque l'on travaille sur une nouvelle fonctionnalité, il est normal d'avoir à intervenir sur différents fichiers. Plusieurs fichiers peuvent donc être concernés par un même commit. Mais il est aussi possible de se rendre compte d'une erreur à un autre niveau ou encore d'une faute d'orthographe dans les textes que l'on s'empresse de corriger. Pourtant, ces actions n'ont rien à voir avec la fonctionnalité que l'on est en train de développer... Et bien notre zone de staging va nous servir de zone tampon, de zone de stockage. On y ajoute tous les fichiers concernant la fonctionnalité en cours sans ajouter les autres fichiers modifiés pour d'autres raisons qui se retrouvent également présents dans notre espace de travail. On prépare ainsi un paquet de fichiers qui a du sens et qu'on est prêt à envoyer en cadeau à Git avec une belle étiquette comme "Mise en place de la fonctionnalité BlaBla". On peut ensuite réaliser un autre commit avec nos corrections et le nommer en conséquence. On saura ainsi où aller chercher si on souhaite revenir à notre projet avant la fonctionnalité ou revenir sur la correction de l'erreur.
En résumé :
git add, on demande à Git de suivre certains fichiers, c'est-à-dire de
prendre en charge la gestion de l'évolution de ces fichiers,git commit, nous demandons à Git d'enregistrer un snapshot, c'est-à-dire
une photographie instantanée de l'état des fichiers suivis et des les archiver dans une base de données (aucune
des
versions précédentes n'est perdue).Nous avons maintenant sur notre arbre local, la dernière version de notre commit. Nous pourrions tout à fait continuer à travailler en local jusqu'à avoir complètement terminé la résolution d'un bug ou le développement d'une nouvelle fonctionnalité. Une fois ceci fait, nous sommes prêts à envoyer nos modificatins sur un serveur distant particulièrement utile lorsque l'on travaille sur plusieurs postes ou en équipe de plusieurs personnes. Une fois les modifications poussées sur le serveurs distants, elles seront accessibles de tous. Nous allons avoir besoin pour ça de configurer notre serveur distant, aussi appelé remote. L'outil plus utilisé aujourd'hui pour interagir avec Git est GitHub, néanmoins dans le cadre de cette UE, nous allons utiliser le GitLab de l'école. Le principe reste le même.
1. Connectez-vous au GitLab de l'école
Vous allez devoir générer un Personal Access Token pour vous authentifiez lors de vos échanges de fichiers entre votre machine locale et le serveur distant. Dans le menu de gauche des "Paramètres utilisateur" vous avez une entrée "Jetons d'accès". Cliquez dessus et cliquez sur le bouton "Ajouter un jeton". Générez un nouveau jeton avec une date d'expiration lointaine en cochant au minimum read_repository et write_repository. Récupérer votre Token dans le bandeau vert qui s'affiche, vous n'aurez plus d'autres occasions de le voir (si vous rencontrez un problème et que vous perdez votre token, vous devrez en générer un nouveau).
2. Créez un projet : "usrs46".
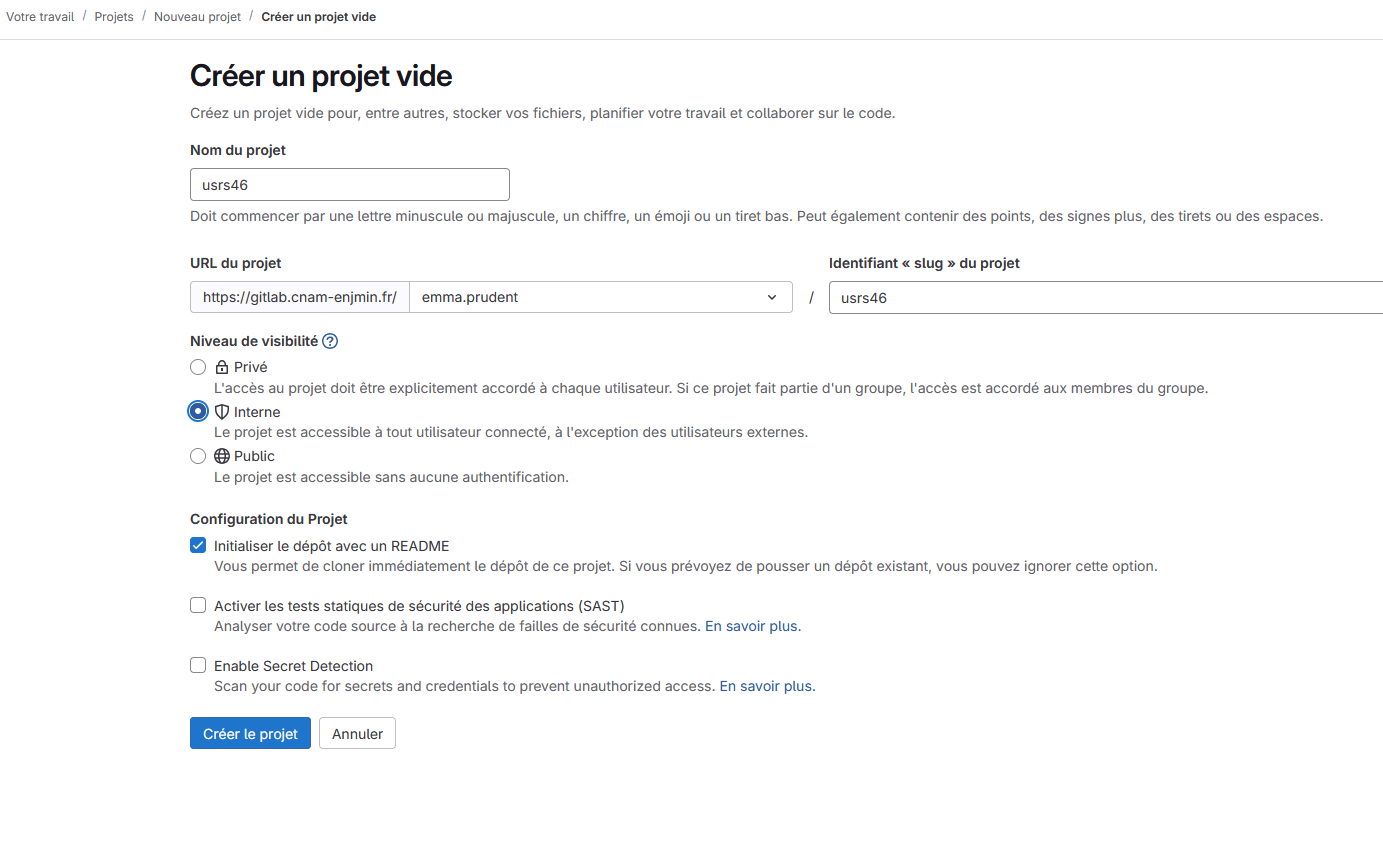
2. Nous allons ensuite informer Git en local de l'emplacement de notre serveur distant. On récupère pour ça l'URL du projet dans gitlab pour le définir comme serveur distant de notre repo local :
git remote add origin https://gitlab.cnam-enjmin.fr/USERNAME/usrs46
git remote -v
origin https://gitlab.cnam-enjmin.fr/USERNAME/usrs46 (fetch)
origin https://gitlab.cnam-enjmin.fr/USERNAME/usrs46 (push)
La commande git remote -v vous permet de vérifier l'URL de votre serveur distant.
Si vous rencontrez une erreur fatal: protocol 'https' is not supported, c'est qu'au moment de
copier/coller l'url de votre serveur distant, vous avez aussi copié des caractères cachés qui empêchent la
connexion.
Supprimez la configuration du serveur distant git remote remove origin et recommancez les étapes
précédentes en vous assurant d'écrire vous même l'url ou de supprimer les caractères cachés via un éditeur de texte
qui les détecte.
3. Commençons par récupérer l'historique distant avec une première commande git pull
git pull --rebase origin main
4. Nous allons ensuite pouvoir envoyer notre premier commit, qui est actuellement encore en local, sur le serveur distant GitLab. Pour cela on utilise la commande git push en précisant le nom de la branche distante. Cette commande vous demandera votre adresse mail et votre Personal Access Token généré plus haut :
git push -u origin main
L'option -u, équivalente à l'option --set-upstream, permet de lier la branche locale main à la branche distante main, ce qui facilite les futurs échanges avec le serveur distant. Elle n'est nécessaire que lors de la première synchronisation entre les branches locales et distantes.
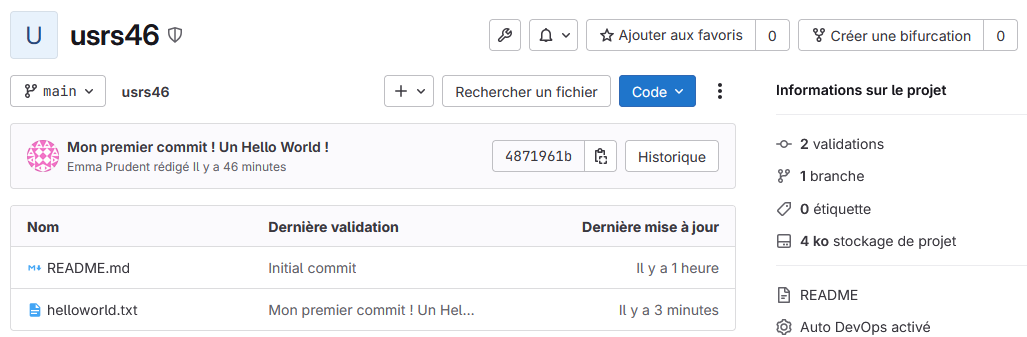
Votre fichier helloworld.txt devrait maintenant être visible sur GitLab.
git config --global user.name "Mon Nom"git config --global user.email "mon.email@example.com"mkdir mon_projet && cd mon_projetgit initgit remote add origin <URL_GITLAB>git remote -vgit pull --rebase origin maingit add <fichier>git commit -m "Message descriptif"git push -u origin maingit add <fichiers_modifiés>git commit -m "Description des modifications"git pushgit pull